
- Sat 23 March 2019
- Experiments
- VSound
Modern electronic house and techno music is highly repetitive. I am not saying that it is, therefore, boring. I am a big fan of certain styles myself! What I am saying is that patterns are being repeated over and over, and it is the variation of the patterns over time that makes this music interesting.
The repetitive nature of electronic music makes some people feel like it is simple, artificial, robotic, almost pre-programmed. It feels like it could have been even generated automatically by a simple algorithm: “take this pattern, repeat 8 times, overlap with another pattern repeated 16 times, slowly fade in the last pattern and repeat it 8 times.”
Researchers in the field of deep learning made huge advances in extracting the structure from images using convolutional neural networks. They have also learned how to generate convincing artificial images using GANs, probabilistic auto-encoders and what not… So, why hasn’t the same progress been achieved with application of deep learning to music? It is easy to imagine that an algorithm could be designed to learn from a sample of music in a certain style, and then learn to generate the music in the same style.
I believe the problem lies with the intermediate representations of patterns in sound that have been attempted so far. Below, I am going to try to explain why, I think, the approaches that attempt to apply deep learning to frequency domain representation of music haven’t had much success (yet).
...
Sound perception is fundamentally different from visual perception in one specific aspect that I think is of the utmost importance. When we look at a picture, we generally perceive the concepts that are present at a specific level of details. For example, we could describe a picture as “a bunch of puppies fighting over a stick on a field of grass with flowers.” The size objects that we perceive as important for representing the picture varies by at most one order of magnitude. We would never think of providing the details of positions of all the blades of grass on which the puppies are playing.
In sound, however, we perceive important features at different scales that vary by many orders of magnitude. We hear the frequencies in the range of 20-20,000 Hz, which spans 10 octaves (lowest frequency is doubles in each subsequent octave). The patterns that we perceive in lower frequencies develop over longer periods of time. The patterns we perceive in higher frequencies might occupy a very short period of time, even shorter than a single cycle of a low frequency. Therefore, analysing sound requires a highly multi-scale approach, and much more so, compared to the approaches we currently use to analyse visual information.
...
Let us look at an idea of applying convolutional networks to music represented in frequency domain… It is easy to say “representation in frequency domain”, but what should that representation be exactly?
In order to detect the low frequencies of 20–40 Hz , we would need to use relatively long windows, say 200ms. However, within such a relatively long time window, a complex pattern consisting of the higher frequencies might occur, such that these higher frequencies change their amplitudes and phases to create a complex composite pattern.
Therefore, if we wanted our machine learning algorithm to capture a pattern of how these higher frequencies change over time, we would necessarily need to use shorter time windows to detect those higher frequencies and their evolution over time. This logic needs to be extended to many orders of magnitude, spanning all 10 octaves.
If we do not apply such multi-scale analysis, we might be able to reproduce the original sound back from the frequency domain (as FFT is invertible). However, our representation in frequency domain will not be continuous over time for the higher frequencies being detected from one window to another. In effect, we loose the information about how the amplitudes and phases of the higher frequencies change over time within the detection window.
In order to obtain frequency domain representation that would be continuous over time for all frequencies being detected, I implemented multi-scale frequency analysis algorithm with shorter detection windows used for shorter frequencies. I think it might we equivalent to a wavelet transform. The amount of frequency domain data extracted larger for higher frequencies. This is needed in order to capture how these frequencies change over time.
...
The frequency domain representations I extracted allow reproducing the original sound almost exactly, both visually in the wave form, and according to the perception of the music being heard. This can also be achieved with FFT. However, additionally, the representation I’ve created allows seeing with much higher details how the higher frequencies evolve over time. The level of information about the frequencies doubles with each octave.
Below you can see examples of frequency domain representations for some sounds. Again, the sound can be reproduced almost exactly from these. The pictures only display the amplitude.
I believe using this representation will enable better applications of deep learning to sound represented in frequency domain. I hope to release a tool soon for converting sound into these multi-scale representations and then loading them from Python for other researchers to use.
Note the exceptional level of details across the time dimension for the higher frequencies.
House beat:

Techno beat and bass:

Thai song:
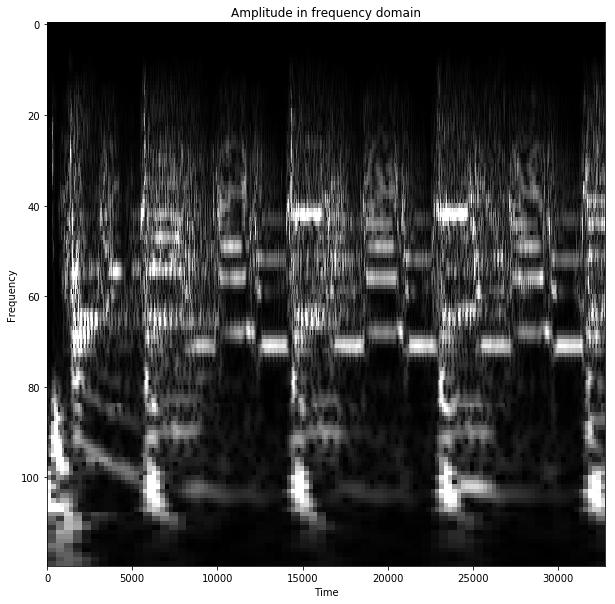
Bach flute:

But why analyse the sound in frequency domain at all? Didn’t the models such as WaveNet show that the sound can be successfully analysed in raw form? I have a conjecture on why analysing the sound in frequency domain might be beneficial…
We perceive the same combination of frequencies shifted up or down in frequency spectrum as “the same instrument playing a different note.” When such notes are represented in wave form, they correspond to the same pattern being shrunk and stretched across time.
Therefore, if we wanted a system that would be able to learn how the same instrument sounds, when playing different notes, and learn the instrument typical sound from the wave representation of music, such machine learning algorithm would necessarily need to have scale-invariance of features built in.
I don’t know of any good models that would allow inferring scale-invariant features across several orders of magnitude. However, if we look at the problem of detecting “the same instrument playing a different note” in frequency representation, different “notes” played by the same instrument simply correspond to shifting the pattern along the y-axis. And this is just location-invariance of features which is easily solved with convolutional neural networks. This provides a solution to a major issue with analysing music across the time scales spanning several orders of magnitude.
I believe that the success of application of deep learning to analysing music will be enabled by better representation of sound in frequency domain and then applying machine learning algorithms that have had success in application to visual data:
-
The frequency domain representations that have been used so far are inadequate for extracting the frequency patterns that are shorter than the detection window used. The new representation will enable multi-scale analysis of music, with higher amount of frequency data for higher frequencies.
-
The frequency domain representation provides a good solution for changing the problem of the scale-invariance of features (hard) to location-invariance of features (easy) in a machine learning model. Making models that provide location-invariance of features is achievable with currently popular models such as convolutional neural networks.
Please leave comments on Medium.